As I mentioned in my previous post, there is going to be a follow up. The focus in this post is going to be more about trying to identify paid accounts who are posting messages to appear as if they are real. It is clear for any regular participant of this community that there are lots of political posts with people having very strong opinions. Many of these accounts have unnatural obsession with certain politicians and political parties to the point that one wonders if these are real people. Detecting such paid accounts definitively is a research problem but I tried to do reasonable analysis to convince myself.
We have code interspersed in this article just to give you an idea as to how this analysis has been done. Part 1 of this article series will give you more information about the data and how it is processed and stored. If you aren't a coder, please feel free to ignore code blocks and simply focus on the pretty graphs and descriptive text. I promise you will still understand what's going on. If you don't, drop me an email and I will try to improve text to clarify whatever is troubling you.
%matplotlib inline
import base64
import matplotlib.pyplot as plt
import sqlite3
import tabulate
from datetime import datetime
from IPython.display import HTML, display
%config InlineBackend.figure_format = 'retina'
def b64decode(m):
return base64.b64decode(m)
conn=sqlite3.connect('reddit.db')
conn.create_function("b64decode", 1, b64decode)
cursor=conn.cursor()
def plot_data(xdata, ydata, xlabel, ylabel, title, kind='bar',
color='blue', width=15, imwidth=12, imheight=4):
fig = plt.figure(figsize=(imwidth, imheight), dpi=80)
fig.suptitle(title, fontsize=20)
plt.xlabel(xlabel, fontsize=18)
plt.ylabel(ylabel, fontsize=16)
plt.bar(xdata, ydata, width=width, color=color)
Participation in Political Submissions during different months
First, the low hanging fruits in determining if there are paid accounts trying to influence people is to see if there is a sudden increase in number of posts at anytime in the past year. As you can see below, there was a sudden spike in participation in political submissions starting April. I tried to see if there was a specific date in April when this started and it turns out that there was a gradual increase. What could have happened that triggered such an increase? Taking average of six months activity before April, there was an increase of ~33% in political submissions. I wondered if this could have been because some political discussions related to demonetization had a different flair. Even including those posts, if we exclude December 2016, there was a definite increase in political submissions since April. I have no conclusive evidence on why this is the case.
# Monthly Political stats
submissions_monthly = cursor.execute("""
select date(posted_at, 'start of month') as month, count(*)
from submissions
where link_flair_text=='Politics' group by month""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in submissions_monthly],
[y for x,y in submissions_monthly],
'Month', 'Submissions', 'Political Submissions Per Month', color='blue')
submissions_monthly = cursor.execute("""
select date(posted_at, 'start of month') as month, count(*)
from submissions
where link_flair_text=='Politics' or link_flair_text=='Demonetization'
group by month""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in submissions_monthly],
[y for x,y in submissions_monthly],
'Month', 'Submissions', 'Political Submissions Per Month incl Demonetization',
color='blue')
submissions_monthly = cursor.execute("""
select date(posted_at) as date, count(*)
from submissions
where link_flair_text=='Politics' and date(posted_at, 'start of month')='2017-04-01'
group by date""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in submissions_monthly],
[y for x,y in submissions_monthly],
'Month', 'Submissions', 'Political Submissions Per Month',
color='blue', width=0.5)



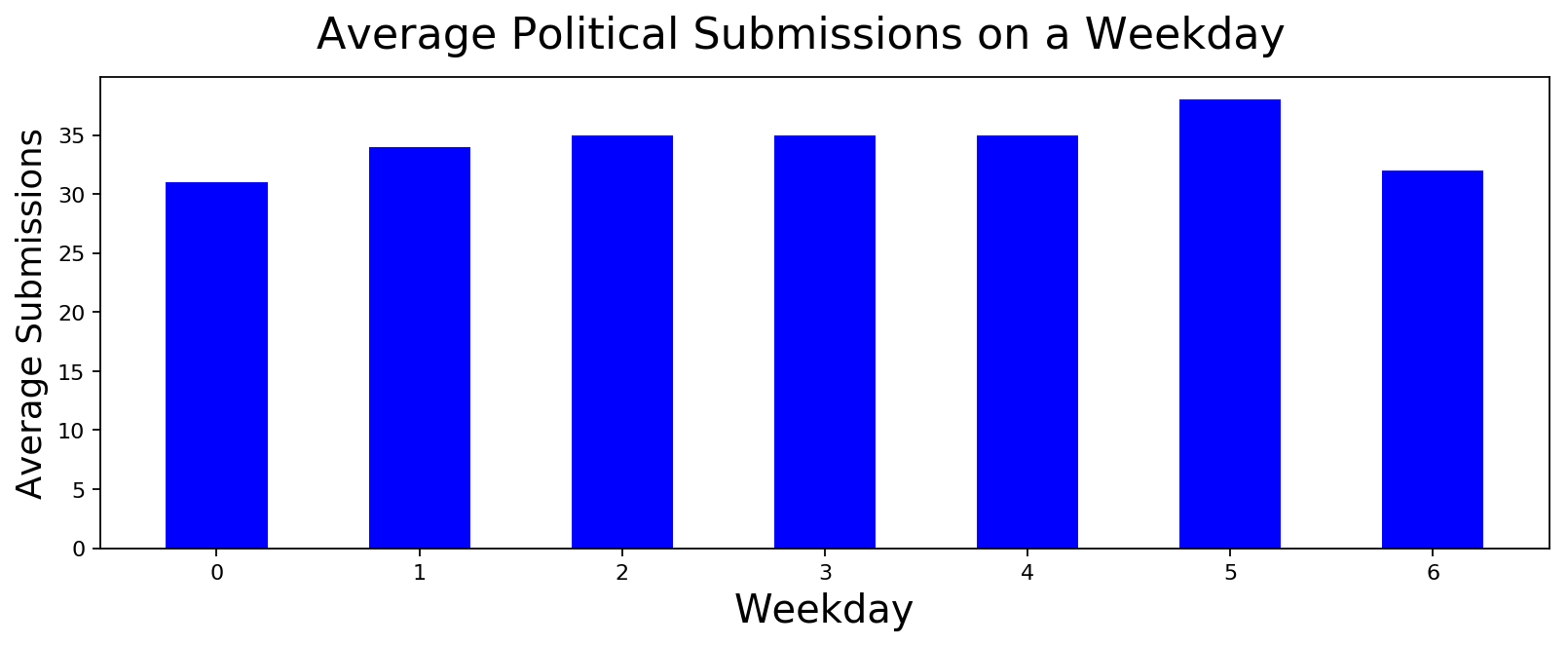
Participation in Political Submissions during an average week
If the increase in participation is primarily due to paid accounts, we should see a dramatic increase in activity during weekdays compared to weekends. The idea is that a regular user will probably continue accessing reddit during weekends as well but not someone whose job is to be on reddit all day. We look at both political submissions and comments to see if we can find some signals. As you can see below, there is a slight increase in activity over the week but nothing over the top to conclude that there are paid accounts. Either these paid accounts are operated all through the week or there are no paid accounts. We don't know yet.
# Weekly stats
submissions_weekday = cursor.execute("""
select weekday,
avg(count) from (select strftime('%w', posted_at) as weekday,
strftime('%W', posted_at) as week, count(*) as count
from submissions
where link_flair_text=='Politics' group by week, weekday)
group by weekday""").fetchall()
plot_data([int(x) for x,y in submissions_weekday],
[int(y) for x,y in submissions_weekday], 'Weekday', 'Average Submissions',
'Average Political Submissions on a Weekday', color='blue', width=0.5)
submissions_weekday = cursor.execute("""
select weekday,
avg(num_comments) from (
select strftime('%w', posted_at) as weekday,
strftime('%W', posted_at) as week,
sum(num_comments) as num_comments
from submissions where link_flair_text=='Politics'
group by week, weekday)
group by weekday""").fetchall()
plot_data([int(x) for x,y in submissions_weekday],
[int(y) for x,y in submissions_weekday], 'Weekday',
'Average Number of Comments',
'Average Political Submission Comments on a Weekday',
color='blue', width=0.5)

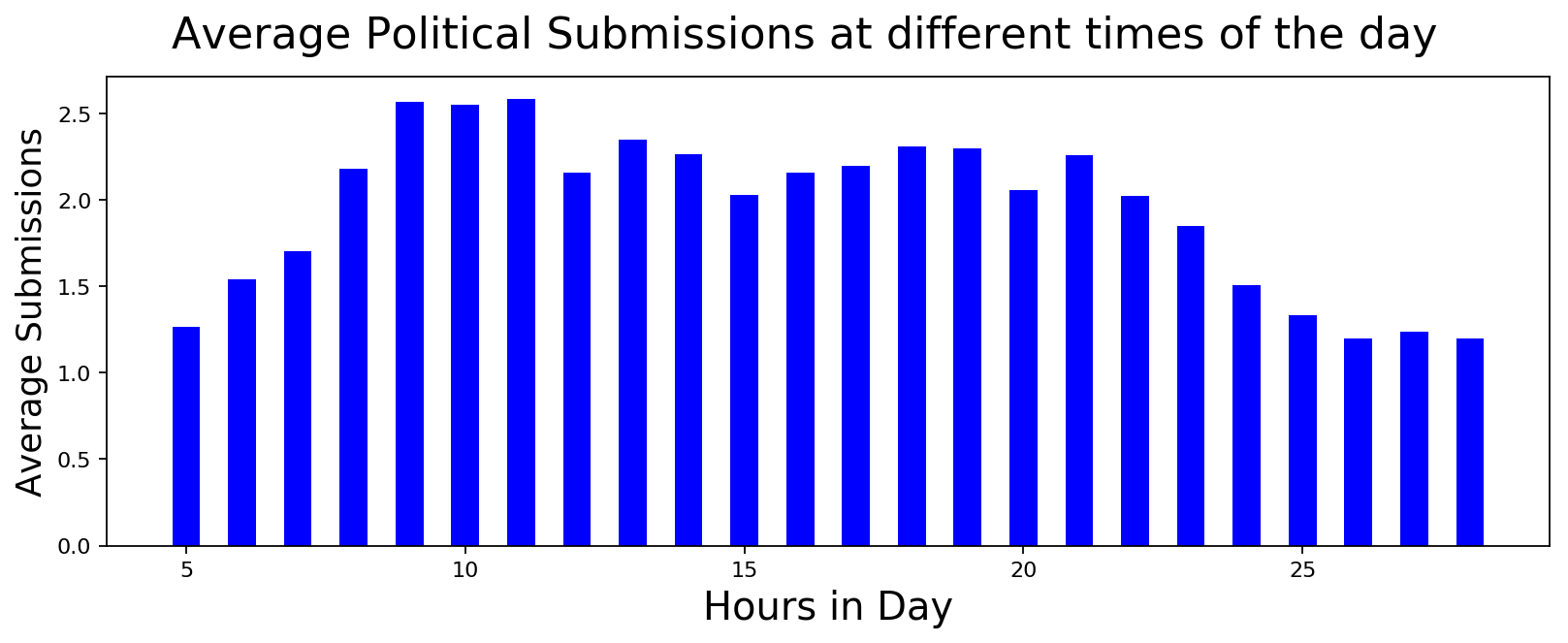
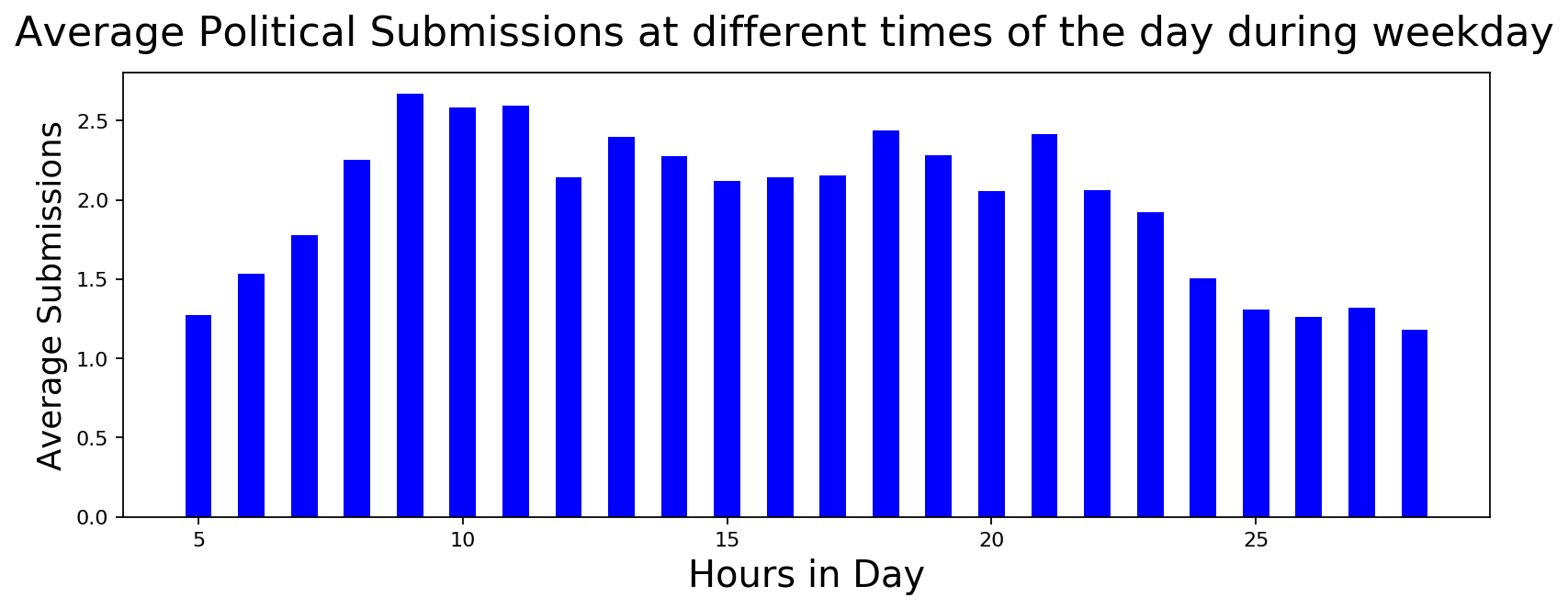
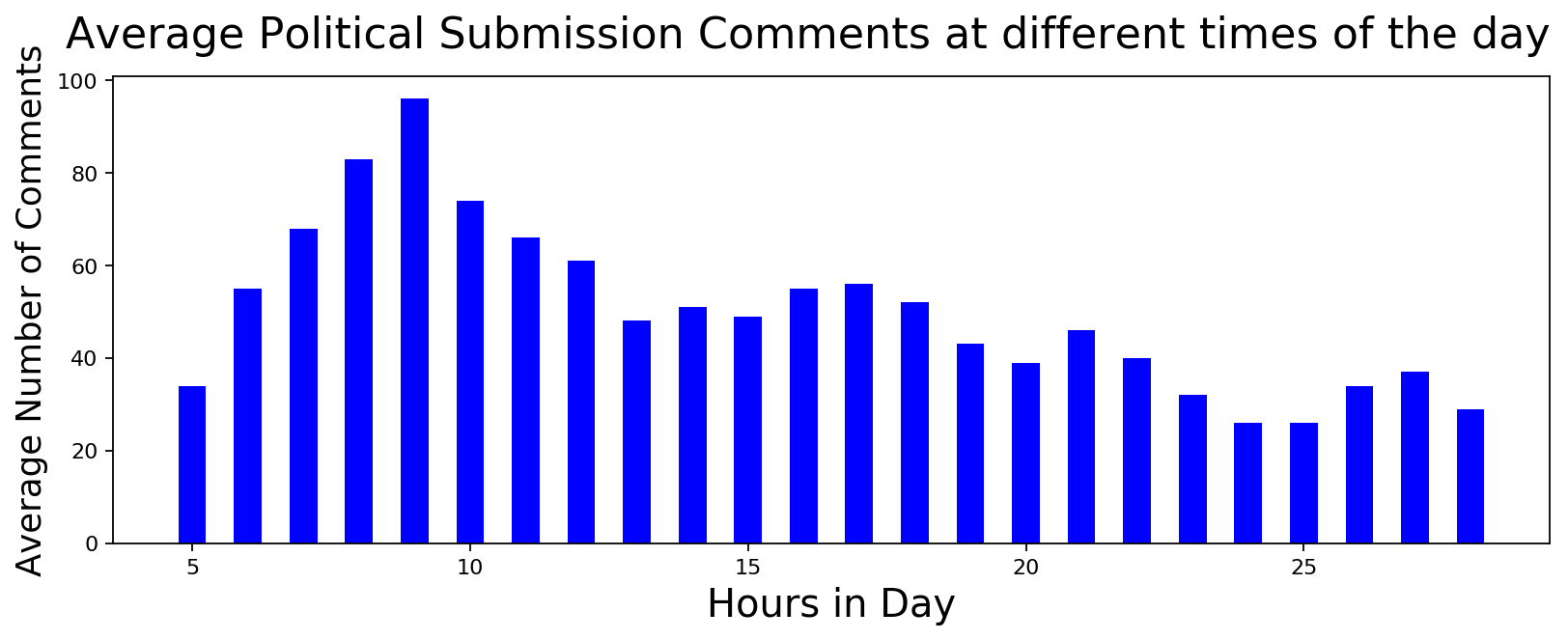
Hourly Participation in Political Submissions
If there was a constant stream of activity during the week, could we find some signal about paid activity if we look at hourly distribution? It turns out that the activity in political submissions seems to match regular non-political activity. And the hourly distribution doesn't give any additional insight into paid user activity. Just to double check, I tried to see if there was a difference in activity during weekday and weekend. Again, no luck.
# Hourly stats
submissions_hourly = cursor.execute("""
select (5.5+hour) as hour,
avg(count) from (
select strftime('%H', posted_at) as hour,
date(posted_at) as date, count(*) as count
from submissions where link_flair_text=='Politics'
group by date, hour)
group by hour""").fetchall()
plot_data([int(x) for x,y in submissions_hourly],
[float(y) for x,y in submissions_hourly],
'Hours in Day', 'Average Submissions',
'Average Political Submissions at different times of the day',
color='blue', width=0.5)
submissions_hourly = cursor.execute("""
select (5.5+hour) as hour, avg(count),
strftime('%w', date) as weekday from (
select strftime('%H', posted_at) as hour,
date(posted_at) as date, count(*) as count
from submissions where link_flair_text=='Politics'
group by date, hour)
where weekday!='0' and weekday!='6'
group by hour""").fetchall()
plot_data([int(x) for x,y,z in submissions_hourly],
[float(y) for x,y,z in submissions_hourly],
'Hours in Day', 'Average Submissions',
'Average Political Submissions at different times of the day during weekday',
color='blue', width=0.5)
submissions_hourly = cursor.execute("""
select (5.5+hour) as hour, avg(num_comments) from (
select strftime('%H', posted_at) as hour,
date(posted_at) as date, sum(num_comments) as num_comments
from submissions where link_flair_text=='Politics'
group by date, hour)
group by hour""").fetchall()
plot_data([int(x) for x,y in submissions_hourly],
[int(y) for x,y in submissions_hourly],
'Hours in Day', 'Average Number of Comments',
'Average Political Submission Comments at different times of the day',
color='blue', width=0.5)
Utterances of different political party names
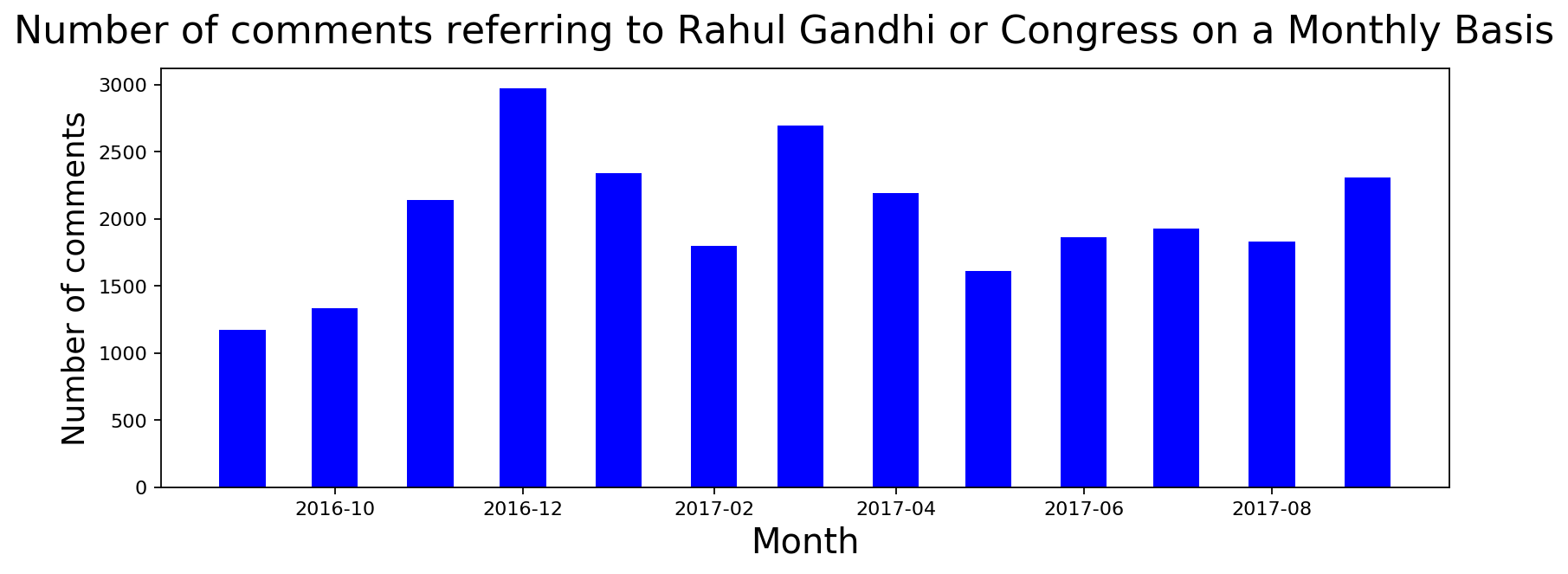
The idea behind this political analysis is to see if there are indeed paid accounts and if so who is paying them. Therefore, we look at the utterance of different political party and leader names to see if there is an isolated upward trend. Unfortunately, both Congress and BJP are showing an upward trend. I think the utterance of these political parties sort of matches their appearance in media. I don't know what to make out of this information. If at all, I would rather not judge with this limited information so as to avoid bias. For some strange reason, APP/Kejriwal saw a significant spike in April followed by a dramatic slowdown. An increase in 400 political submissions per month that we saw in April can probably be attributable to whatever caused this significant upward trend for AAP/Kejriwal.
comment_lengths = cursor.execute("""
select month, count from (
select date(posted_at, 'start of month') as month,
count(*) as count, sum(score) as score, b64decode(content) as b64comment
from comments
where b64comment!='' and (
(b64comment LIKE '%congress%') or (b64comment LIKE '%raga%') or
(b64comment LIKE '%rahul%') or (b64comment LIKE '%gandhi%'))
group by month)""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in comment_lengths],
[int(y) for x,y in comment_lengths], 'Month', 'Number of comments',
'Number of comments referring to Rahul Gandhi or Congress on a Monthly Basis',
color='blue', width=15)
comment_lengths = cursor.execute("""
select month, count from (
select date(posted_at, 'start of month') as month, count(*) as count,
sum(score) as score, b64decode(content) as b64comment
from comments
where b64comment!='' and ((b64comment LIKE '%bjp%') or
(b64comment LIKE '%modi%') or (b64comment LIKE '%namo%'))
group by month)""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in comment_lengths],
[int(y) for x,y in comment_lengths], 'Month', 'Number of comments',
'Number of comments referring to Modi or BJP on a Monthly Basis',
color='blue', width=15)

comment_lengths = cursor.execute("""
select
month, count
from (
select
date(posted_at, 'start of month') as month,
count(*) as count, sum(score) as score,
b64decode(content) as b64comment
from comments
where b64comment!='' and (
(b64comment LIKE '%aap%') or (b64comment LIKE '%aadmi%') or
(b64comment LIKE '%kejri%') or (b64comment LIKE '%kejriwal%'))
group by month)""").fetchall()
plot_data([datetime.strptime(x, '%Y-%m-%d') for x,y in comment_lengths],
[int(y) for x,y in comment_lengths], 'Month', 'Number of comments',
'Number of comments referring to Kejriwal or AAP on a Monthly Basis',
color='blue', width=15)

We looked at number of submissions and comments across different time periods but can we find some signal in the length of the comment? If at all there are paid accounts, what are they measured on? Could it be length of the comment? If so we should see quite a lot of long comments or comments over certain length. So let's see...
comment_lengths = cursor.execute("""
select
comment_length, count(*) as count
from (
select
length(content) as comment_length
from comments where content!='')
group by comment_length
order by comment_length asc limit 100""").fetchall()
plot_data([int(x) for x,y in comment_lengths],
[int(y) for x,y in comment_lengths],
'Length of comment', 'Number of comments',
'Histogram of length of all the comments',
color='blue', width=0.5)

It turns out that other than a spike at length of comment between 10 and 15, nothing else stands out. Let's see what's the case with those specific comments of length between 10 and 15 by constructing a word cloud of those comments.
# Submission text word cloud
submission_text = ''
for b64text in cursor.execute("""
select content from comments
where content!='' and length(content)>10 and length(content)<15""").fetchall():
text = base64.b64decode(b64text[0])
submission_text += text + ' '
text_wordcloud = WordCloud(
width=1200, height=600, background_color='white').generate(submission_text)
fig = plt.figure(figsize=(12,6), dpi=80)
plt.imshow(text_wordcloud, interpolation='bilinear')
plt.title('Wordcloud of Political Submission Content', fontsize=20)
plt.axis("off")
Output:
(-0.5, 1199.5, 599.5, -0.5)

Well, looks like most of those comments are 'removed', 'deleted', etc., unrelated to the discussion at hand. I guess, if paid accounts exist, they are definitely not paid by the length of their comments. It did match my intuition but its not a big deal to validate it.
Submission Authors and their Activity
Focusing on general user activity didn't lead to any information that makes it easy to identify paid accounts. Let's try focusing on authors who posted most submissions. We can look at authors based on their submissions or the score that they received. Below is the list of authors with highest political submissions and scores.
# Most frequent political submission authors
data = cursor.execute("""
select posted_by, count(*) as count
from submissions
where link_flair_text=='Politics'
group by posted_by order by count desc""").fetchmany(11)[1:]
display(HTML(
tabulate.tabulate(data,
headers=['Username', 'Submissions'], tablefmt='html')))
| Username | Submissions |
|---|---|
| swacchreddit | 330 |
| gcs8 | 261 |
| modiusoperandi | 249 |
| pannagasamir | 229 |
| hipporama | 203 |
| pure_haze | 189 |
| TemptNotTheBlade | 173 |
| aryaninvader | 163 |
| ajfben | 153 |
| darklordind | 145 |
# Most popular (based on score) political submission authors
data = cursor.execute("""
select posted_by, sum(score) as score
from submissions
group by posted_by order by score desc""").fetchmany(11)[1:]
display(HTML(
tabulate.tabulate(data,
headers=['Username', 'Submission Score'], tablefmt='html')))
| Username | Submission Score |
|---|---|
| hipporama | 43363 |
| pannagasamir | 34396 |
| wordswithmagic | 28209 |
| aryaninvader | 26022 |
| TemptNotTheBlade | 22450 |
| gcs8 | 22383 |
| ironypatrol | 21829 |
| modiusoperandi | 21447 |
| spikyraccoon | 19153 |
| ab0mI | 17806 |
Author Affinity
Could any of the above identified accounts have secondary accounts that they use to push up their submissions? Secondary accounts are the ones whose sole purpose is to upvote, comment or respond to authors posts to give an impression that the post is seeing more activity than it actually does. Unfortunately, Reddit doesn't share upvote/downvote information so we are left with looking at who responded to whom. In order to make this analysis easier, I came up with Author Affinity Score. Basically, for every author A, we try to identify proportion of responses that an author B received from A. If A responds solely to B, it could be that A is a secondary account of B. To put it mathematically,
Author Affinity of A to B = (Number of responses of Author A to Author B) / (Number of all responses of Author A)
We look at the distribution of author affinity score to see if we can see some patterns. Please note that this information is not necessarily conclusive as there could be some accounts that were created just to participate in certain threads and never used again. It doesn't imply that the account is related to the author. However, it is interesting to note that there are quite a few accounts like that.
I apologize about long SQL queries from here onwards. As you can see, these queries are really complicated and it is hard for me to understand them fully unless I indent them properly.
# Secondary accounts
data = cursor.execute("""
select (max_specific_response*1.0/total_responses) as author_affinity,
count(*) as count
from
(select
comments.posted_by,
count(*) as total_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
group by
comments.posted_by)
join
(
select
c_posted_by,
max(specific_responses) as max_specific_response
from
(select
comments.posted_by as c_posted_by,
(comments.posted_by||submissions.posted_by) as pair,
count(*) as specific_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
and comments.posted_by!=submissions.posted_by
group by
pair)
group by
c_posted_by)
on posted_by==c_posted_by
where
total_responses > 10
group by
author_affinity
""").fetchall()
plot_data([float(x) for x,y in data],
[int(y) for x,y in data],
'Author Affinity score', 'Number of Comments',
'Affinity of an author to another specific author',
color='blue', width=0.01)

Now, lets look at accounts which have a strong affinity to an author and made large number of comments. If an account made few comments and has strong affinity, we can consider that as a one-off account to respond. However, if an account has large number of submissions and still has strong affinity to an author, that's definitely a reason to be suspicious about. And we have quite a few such accounts. Some of these accounts are obviously secondary accounts. For ex., "RahulRamIO" and "NikhilRaoIO" are most probably secondary accounts. Is there an actual parent account that owns all these? We don't know yet. It needs much more investigation.
# Affinity of authors sorted by affinity score and total responses
data = cursor.execute("""
select posted_by,
total_responses,
s_posted_by,
max_specific_response,
(max_specific_response*1.0/total_responses) as author_affinity
from
(select
comments.posted_by,
count(*) as total_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
group by
comments.posted_by)
join
(
select
c_posted_by,
s_posted_by,
max(specific_responses) as max_specific_response
from
(select
comments.posted_by as c_posted_by,
submissions.posted_by as s_posted_by,
(comments.posted_by||submissions.posted_by) as pair,
count(*) as specific_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
and comments.posted_by!=submissions.posted_by
group by
pair)
group by
c_posted_by)
on posted_by==c_posted_by
where
total_responses>1
order by
author_affinity desc,
total_responses desc""").fetchmany(100)
display(HTML(
tabulate.tabulate(data,
headers=[
'Comment Author', 'Total Comments', 'Submission Author',
'Responses', 'Author Affinity'], tablefmt='html')))
| Comment Author | Total Comments | Submission Author | Responses | Author Affinity |
|---|---|---|---|---|
| doGrmoctidder | 87 | notmuchhere_carryon | 87 | 1 |
| RahulRamIO | 37 | NikhilRaoIO | 37 | 1 |
| ashwinskumar | 34 | theunrealtimes | 34 | 1 |
| rajkummar_r | 33 | vikramaditya_m | 33 | 1 |
| Bu-D-Yo-Eve-Lift | 30 | [deleted] | 30 | 1 |
| monkey_sage | 28 | Devam13 | 28 | 1 |
| Leoelement02 | 26 | so_mindfucked | 26 | 1 |
| D3MON130 | 21 | Millicent_Bystandard | 21 | 1 |
| hatebreeder69 | 19 | notmuchhere_carryon | 19 | 1 |
| verylateish | 19 | so_mindfucked | 19 | 1 |
| ThatGuyGaren | 16 | rajutek | 16 | 1 |
| aniruddhdodiya | 16 | N-Mag | 16 | 1 |
| boobanies1234 | 16 | saptarsi | 16 | 1 |
| paramour_u | 16 | thewire_in | 16 | 1 |
| 91JustCurious | 15 | backFromTheBed | 15 | 1 |
| barebearbeard | 15 | Devam13 | 15 | 1 |
| vidyavolks | 15 | eve2k17 | 15 | 1 |
| weneedtofederalize | 14 | so_mindfucked | 14 | 1 |
| wubbalubbaeatadick | 13 | awkwardpile | 13 | 1 |
| CrazedZombie | 12 | rajutek | 12 | 1 |
| Ni-li | 12 | oxeam | 12 | 1 |
| firenhammer | 12 | sanskaridaddy | 12 | 1 |
| statelessnfaithless | 12 | japanese_kuhukuhu | 12 | 1 |
| stealtho | 12 | jrulz254 | 12 | 1 |
| venkrish | 12 | throwawayindia11 | 12 | 1 |
| wingdbullet | 12 | Rpittrer | 12 | 1 |
| AbhijeetBarse | 11 | abhishekiyer | 11 | 1 |
| Luk-SpringWalker | 11 | Pygnus | 11 | 1 |
| ThrottleMunky | 11 | prawncream | 11 | 1 |
| amrams | 11 | saptarsi | 11 | 1 |
| modomario | 11 | so_mindfucked | 11 | 1 |
| poetrytadka | 11 | thrownwa | 11 | 1 |
| shakeeshakee | 11 | stoikrus1 | 11 | 1 |
| vimalnair | 11 | eve2k17 | 11 | 1 |
| vineetr | 11 | redweddingsareawesom | 11 | 1 |
| Ant-Climax | 10 | SB-bhakt | 10 | 1 |
| CaptainBoomrang | 10 | SoulsBorNioh | 10 | 1 |
| DivyDubey | 10 | [deleted] | 10 | 1 |
| FranciscoEverywhere | 10 | Devam13 | 10 | 1 |
| TheAsteroid | 10 | notmuchhere_carryon | 10 | 1 |
| chin-ke-glasses | 10 | so_mindfucked | 10 | 1 |
| ePi7 | 10 | aucolgera | 10 | 1 |
| hexalby | 10 | so_mindfucked | 10 | 1 |
| lordpimba | 10 | Pygnus | 10 | 1 |
| mapzv | 10 | pysthrwaway | 10 | 1 |
| sreyatheresa | 10 | eve2k17 | 10 | 1 |
| thairsadam | 10 | balamz | 10 | 1 |
| vivek1982 | 10 | NikhilRaoIO | 10 | 1 |
| Apiperofhades | 9 | HarrySeverusPotter | 9 | 1 |
| Mascatuercas | 9 | so_mindfucked | 9 | 1 |
| Mina-Harad | 9 | prawncream | 9 | 1 |
| MrBoonio | 9 | so_mindfucked | 9 | 1 |
| Some_Random_Nob | 9 | aphnx | 9 | 1 |
| devGRASS | 9 | aeborn_man | 9 | 1 |
| mik-1 | 9 | saptarsi | 9 | 1 |
| peculiarblend | 9 | doc_two_thirty | 9 | 1 |
| sauputt | 9 | anon_geek | 9 | 1 |
| ECWS | 8 | burdeamit | 8 | 1 |
| HSBCIndia | 8 | gatechguy | 8 | 1 |
| Hohenes | 8 | so_mindfucked | 8 | 1 |
| LawDallason | 8 | oxeam | 8 | 1 |
| Warlizard | 8 | mean_median | 8 | 1 |
| ZippyDan | 8 | spikyraccoon | 8 | 1 |
| chah-pohe | 8 | avinassh | 8 | 1 |
| dasoberirishman | 8 | Devam13 | 8 | 1 |
| ollywollypollywoggy | 8 | Devam13 | 8 | 1 |
| oreng | 8 | TheAustroHungarian1 | 8 | 1 |
| thegoodbadandsmoggy | 8 | iNotRobot | 8 | 1 |
| zzzzzzzzzzzzzzzzspaf | 8 | so_mindfucked | 8 | 1 |
| Afteraffekt | 7 | RealPhiLee | 7 | 1 |
| Arnorien16 | 7 | prateek_gosh | 7 | 1 |
| AuswinGThomas | 7 | notmuchhere_carryon | 7 | 1 |
| BamboDaClown | 7 | Sid_da_bomb | 7 | 1 |
| Blaxrobe | 7 | Devam13 | 7 | 1 |
| Elvaga | 7 | Pygnus | 7 | 1 |
| IndiaIsSaffron | 7 | notmuchhere_carryon | 7 | 1 |
| KaroshiNakamoto | 7 | saptarsi | 7 | 1 |
| Lucas_Berse | 7 | Pygnus | 7 | 1 |
| NewsForThePaperGod | 7 | notmuchhere_carryon | 7 | 1 |
| Penk | - 7 | so_mindfucked | 7 | 1 |
| Pmbreddit | 7 | parvdave | 7 | 1 |
| ScamJamSlam | 7 | saptarsi | 7 | 1 |
| amalthebear | 7 | john2a | 7 | 1 |
| aut1sticalex | 7 | peopledontlikemypost | 7 | 1 |
| dudegrt | 7 | asherkosaraju | 7 | 1 |
| elcrankopunko | 7 | anon_geek | 7 | 1 |
| jangood | 7 | threedotsguy | 7 | 1 |
| kj_venom11 | 7 | backFromTheBed | 7 | 1 |
| madboy1995 | 7 | sunil24 | 7 | 1 |
| mbok_jamu | 7 | Devam13 | 7 | 1 |
| nibbler97 | 7 | spikyraccoon | 7 | 1 |
| over9E3 | 7 | justamomentbee | 7 | 1 |
| ppatra_ka_Jijaji | 7 | ppatra | 7 | 1 |
| realisticview | 7 | AvianSlam | 7 | 1 |
| sakht_launda | 7 | backFromTheBed | 7 | 1 |
| samarhalarnkar | 7 | govindrajethiraj | 7 | 1 |
| spl0i7 | 7 | avinassh | 7 | 1 |
| throwawayredac11 | 7 | throwawayredac1 | 7 | 1 |
| xingfenzhen | 7 | so_mindfucked | 7 | 1 |
| AQKhan786 | 6 | TragedyOfAClown | 6 | 1 |
Author Affinity and Average Time to Respond
We have quite a lot of accounts with high author affinity score. If these accounts are indeed used for pushing up a submission to earn that sweet karma, we can look at the average time to respond as an indicator. For all the probable secondary accounts identified so far, lets also include the average time to respond to the original accounts submission. For this, we are only considering accounts that made more than one submission. This excludes one-off accounts that bias the results.
# Secondary account count of different authors based on affinity score
data = cursor.execute("""
select s_posted_by,
count(*) as count,
avg(avg_timediff) as avg_avg_timediff
from
(select
s_posted_by,
posted_by,
(max_specific_response*1.0/total_responses) as author_affinity,
avg_timediff
from
(select
comments.posted_by,
count(*) as total_responses,
avg((
cast(strftime('%s', comments.posted_at) as integer) -
cast(strftime('%s', submissions.posted_at) as integer))/60) as avg_timediff
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
group by
comments.posted_by)
join
(
select
c_posted_by,
s_posted_by,
max(specific_responses) as max_specific_response
from
(select
comments.posted_by as c_posted_by,
submissions.posted_by as s_posted_by,
(comments.posted_by||submissions.posted_by) as pair,
count(*) as specific_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
where
comments.posted_by!=submissions.posted_by
group by
pair)
group by
c_posted_by)
on posted_by==c_posted_by
where
total_responses>1
)
where
author_affinity > 0.9
group by
s_posted_by
order by
count desc
""").fetchmany(100)
display(HTML(
tabulate.tabulate(data,
headers=[
'Submission Poster', 'Probable Secondary Accounts',
'Avg time to respond in mins'], tablefmt='html')))
| Submission Poster | Probable Secondary Accounts | Avg time to respond |
|---|---|---|
| so_mindfucked | 76 | 2636.49 |
| Devam13 | 63 | 2452.89 |
| [deleted] | 61 | 1762.73 |
| spikyraccoon | 47 | 704.677 |
| notmuchhere_carryon | 40 | 1772.21 |
| Pygnus | 39 | 580.256 |
| avinassh | 39 | 3287.31 |
| doc_two_thirty | 28 | 871.147 |
| saptarsi | 27 | 1391.25 |
| wordswithmagic | 20 | 610.322 |
| backFromTheBed | 19 | 1330.52 |
| RealPhiLee | 17 | 993.681 |
| rajutek | 16 | 1196.14 |
| ppatra | 15 | 13633.7 |
| oxeam | 14 | 6533.38 |
| ARflash | 13 | 2290.14 |
| Thisisbhusha | 11 | 6281.81 |
| cool_boyy | 10 | 1855.47 |
| prawncream | 10 | 559.791 |
| OnePunchSenpai | 9 | 829.509 |
| Lotus_towers | 8 | 452.038 |
| why_so_sirious | 8 | 2595.46 |
| anon_geek | 8 | 3969.31 |
| goenkasandeep | 8 | 543.717 |
| ironypatrol | 8 | 7289.61 |
| parvaaz | 8 | 76.2778 |
| parvdave | 8 | 299.729 |
| thelonesomeguy | 8 | 15540.6 |
| vikramaditya_m | 8 | 33.9341 |
| yal_sik | 8 | 1972.27 |
| BharatiyaNagarik | 7 | 563.536 |
| SanskariNari | 7 | 575.333 |
| bhogle-harsha | 7 | 116.929 |
| hipporama | 7 | 540.524 |
| hoezaaay | 7 | 53.0476 |
| i_am_not_sam | 7 | 1516.68 |
| pannagasamir | 7 | 747.429 |
| root_su | 7 | 730.19 |
| shashitharoor2017 | 7 | 145.786 |
| Keerikkadan91 | 6 | 991.525 |
| NikhilRaoIO | 6 | 64.5099 |
| arrangedmarriagescar | 6 | 2865.94 |
| indifferentoyou | 6 | 1037.99 |
| majorwtf | 6 | 501.389 |
| rex_trillerson | 6 | 670.5 |
| 1975edbyreddit | 5 | 1217.82 |
| aryaninvader | 5 | 1099.99 |
| in3po | 5 | 602.3 |
| in3xorabl3 | 5 | 1996.59 |
| ponniyin_selvan | 5 | 1410.22 |
| ribiy | 5 | 1265.4 |
| theunrealtimes | 5 | 31.8725 |
| yogesh_calm | 5 | 3790.1 |
| 2EyedRaven | 4 | 21241.1 |
| ENTKulcha | 4 | 1510.77 |
| Gyanam | 4 | 5246.83 |
| Kulcha__Warrior | 4 | 4973.83 |
| Phuc-Dat_Bich | 4 | 392.708 |
| Saigo_Digiart | 4 | 332.042 |
| Sykik165 | 4 | 496.7 |
| Voiceofstray | 4 | 1334.25 |
| YouKiddin | 4 | 1180.21 |
| _dexter | 4 | 1530.12 |
| aucolgera | 4 | 659.125 |
| babbanbhai | 4 | 722.833 |
| bad_joke_maker | 4 | 632.458 |
| dopamine86 | 4 | 949 |
| eve2k17 | 4 | 13.4826 |
| lallulal | 4 | 1054.25 |
| modiusoperandi | 4 | 523.625 |
| nuclearpowerwalah | 4 | 1949.25 |
| redindian92 | 4 | 325.25 |
| sIlentr3b3l | 4 | 746.375 |
| shashi_sah | 4 | 4900.42 |
| sorry_shaktimaan | 4 | 565.125 |
| start123 | 4 | 686.792 |
| unknown-indian | 4 | 1326.27 |
| vinodis | 4 | 269.708 |
| z921 | 4 | 2087.42 |
| -0-1- | 3 | 6725.67 |
| 47884375 | 3 | 625.667 |
| AAPkeMoohMe | 3 | 487.25 |
| Aamraswala | 3 | 410.5 |
| Abzone7n | 3 | 1894.5 |
| AvianSlam | 3 | 18878.4 |
| Chutiyapaconnoisseur | 3 | 9667.33 |
| HarrySeverusPotter | 3 | 574.685 |
| HornOK | 3 | 598.333 |
| Improctor | 3 | 4672.5 |
| LOLR556 | 3 | 3692.33 |
| SD548 | 3 | 1893.91 |
| TheAustroHungarian1 | 3 | 903.125 |
| 0110111001101111 | 3 | 347.833 |
| aham_brahmasmi | 3 | 1189.83 |
| baba_ranchoddas | 3 | 330.056 |
| bathroomsinger | 3 | 106435 |
| dhakkarnia | 3 | 885.444 |
| dodunichaar | 3 | 1049.83 |
| ghatroad | 3 | 400 |
| hedButt | 3 | 761.222 |
Well, that doesn't make sense. If someone created so many secondary accounts, one would assume that they would respond soon after the submission was made. However, what we see here is that the secondary accounts usually respond few hours AFTER the submission. Sometimes even after couple of days. Why would that be? Is it because someone is using these secondary accounts only to ensure that the discussion continues and that the submission stays longer on the front-page? Before we answer that, lets look at a specific author and his secondary accounts so we have a better idea of what we are looking at. Some of the accounts identified above are moderators and there were some AMAs and Cultural Exchange threads so their secondary accounts can be explained that way. I picked a non-mod author with large number of secondary accounts and with low time to respond, just as an example. That lucky author turned out to be "wordswithmagic".
# Secondary account count of different authors based on affinity score
data = cursor.execute("""
select
s_posted_by, posted_by, total_responses, max_specific_response,
author_affinity, avg_timediff
from
(select
s_posted_by,
posted_by,
total_responses,
max_specific_response,
(max_specific_response*1.0/total_responses) as author_affinity,
avg_timediff
from
(select
comments.posted_by,
count(*) as total_responses,
avg((
cast(strftime('%s', comments.posted_at) as integer) -
cast(strftime('%s', submissions.posted_at) as integer))/60) as avg_timediff
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
group by
comments.posted_by)
join
(
select
c_posted_by,
s_posted_by,
max(specific_responses) as max_specific_response
from
(select
comments.posted_by as c_posted_by,
submissions.posted_by as s_posted_by,
(comments.posted_by||submissions.posted_by) as pair,
count(*) as specific_responses
from
comments
join
submissions
on comments.submission_id==submissions.submission_id
where
comments.posted_by!=submissions.posted_by
group by
pair)
group by
c_posted_by)
on posted_by==c_posted_by
)
where
s_posted_by=='wordswithmagic'
and author_affinity > 0.9
and total_responses > 1
order by
total_responses desc,
author_affinity desc
""").fetchmany(20)
display(HTML(
tabulate.tabulate(data,
headers=[
'Comment Author', 'Total Comments', 'Submission Author',
'Responses', 'Author Affinity', 'Avg time to respond'], tablefmt='html')))
| Comment Author | Submission Author | Total Comments | Responses | Author Affinity | Avg time to respond |
|---|---|---|---|---|---|
| wordswithmagic | strudel- | 5 | 5 | 1 | 436.2 |
| wordswithmagic | Shiroi_Kage | 4 | 4 | 1 | 940.75 |
| wordswithmagic | euronforpresident | 4 | 4 | 1 | 706.75 |
| wordswithmagic | redstarturns | 4 | 4 | 1 | 191.75 |
| wordswithmagic | SaorAlba138 | 3 | 3 | 1 | 836 |
| wordswithmagic | delusion4 | 3 | 3 | 1 | 412.333 |
| wordswithmagic | fleshnbones | 3 | 3 | 1 | 847.333 |
| wordswithmagic | r3dsm0k3 | 3 | 3 | 1 | 254 |
| wordswithmagic | wohho | 3 | 3 | 1 | 528.333 |
| wordswithmagic | 25sittinon25cents | 2 | 2 | 1 | 1206 |
| wordswithmagic | Bodygasm | 2 | 2 | 1 | 292.5 |
| wordswithmagic | Coltonhoover | 2 | 2 | 1 | 2083.5 |
| wordswithmagic | Gustomaximus | 2 | 2 | 1 | 627 |
| wordswithmagic | Skay_4 | 2 | 2 | 1 | 389.5 |
| wordswithmagic | gummz | 2 | 2 | 1 | 233 |
| wordswithmagic | ireadfaces | 2 | 2 | 1 | 124 |
| wordswithmagic | mumra71294 | 2 | 2 | 1 | 400 |
| wordswithmagic | screenpoet | 2 | 2 | 1 | 429.5 |
| wordswithmagic | tiberseptim1 | 2 | 2 | 1 | 724.5 |
| wordswithmagic | wowmansohacked | 2 | 2 | 1 | 543.5 |
Looking at comments from a specific secondary account called 'strudel-', just to see if the comments add any value to the discussion. If they don't, it may mean that these accounts are there just to further the discussion. Well, as you can see below, it isn't clear if this is indeed secondary account of wordswithmagic. As I mentioned earlier, these are just probable secondary accounts. We need lot more data analysis to prove it conclusively that these are indeed secondary accounts of an author.
# Secondary account count of different authors based on affinity score
data = cursor.execute("""
select b64decode(content) as b64 from comments where posted_by=='strudel-'
""").fetchmany(20)
display(HTML(tabulate.tabulate(data, headers=['Comment'], tablefmt='html')))
Comment
Just like they do in the US. http://www.nj.com/hunterdon-county-democrat/index.ssf/2012/12/divorcee_sits_in_jail_while_ua.html Very common actually. https://www.youtube.com/watch?v=uI80NWf7giM
He's not going to answer your question, he's going to resort to baseless shaming tactics like most of these morons do.
Depends, does her hand have a penis?
If two people are drunk and having sex, are they raping eachother?
That's why marriage rates are dropping drastically and people are going /r/mgtow
Average Active Time of a Submission
If someone has secondary accounts and they are not using them to promote their submission, as we found out, they maybe using those accounts to keep the thread alive. If that's the case, active time of a submission, which is the time difference between when the submission is made and the last comment is made, should be the one that is being gamed. This ensures that visitors to the subreddit see the submission for much longer than they would have otherwise. So let's see if there is a pattern here...
comment_diffs = cursor.execute("""
select active_time, count(*)
from
(select submission_id, max(timediff) as active_time
from
(select
d.posted_by, c.submission_id,
(
cast(strftime('%s', c.posted_at) as integer) -
cast(strftime('%s', d.posted_at) as integer)
)/60 as timediff
from
comments as c
join
submissions as d on c.submission_id==d.submission_id
where
c.posted_by!='AutoModerator'
and c.posted_by NOT LIKE '%bot'
and c.posted_by!='[deleted]')
group by
submission_id)
where active_time > 10
group by active_time
order by active_time asc
""").fetchmany(2000)
plot_data([int(x) for x,y in comment_diffs],
[int(y) for x,y in comment_diffs],
'Active time in minutes', 'Number of submissions',
'Distribution of Active Time of All Submissions',
color='blue', width=1.0)
comment_diffs = cursor.execute("""
select active_time, count(*)
from
(select submission_id, max(timediff) as active_time
from
(select
d.posted_by, c.submission_id,
(
cast(strftime('%s', c.posted_at) as integer) -
cast(strftime('%s', d.posted_at) as integer)
)/60 as timediff
from
comments as c
join
submissions as d on c.submission_id==d.submission_id
where
c.posted_by!='AutoModerator'
and c.posted_by NOT LIKE '%bot'
and c.posted_by!='[deleted]'
and d.link_flair_text='Politics')
group by
submission_id)
where active_time > 10
group by active_time
order by active_time asc
""").fetchmany(2000)
plot_data([int(x) for x,y in comment_diffs],
[int(y) for x,y in comment_diffs],
'Active time in minutes', 'Number of submissions',
'Distribution of Active Time of Political Submissions',
color='blue', width=1.0)
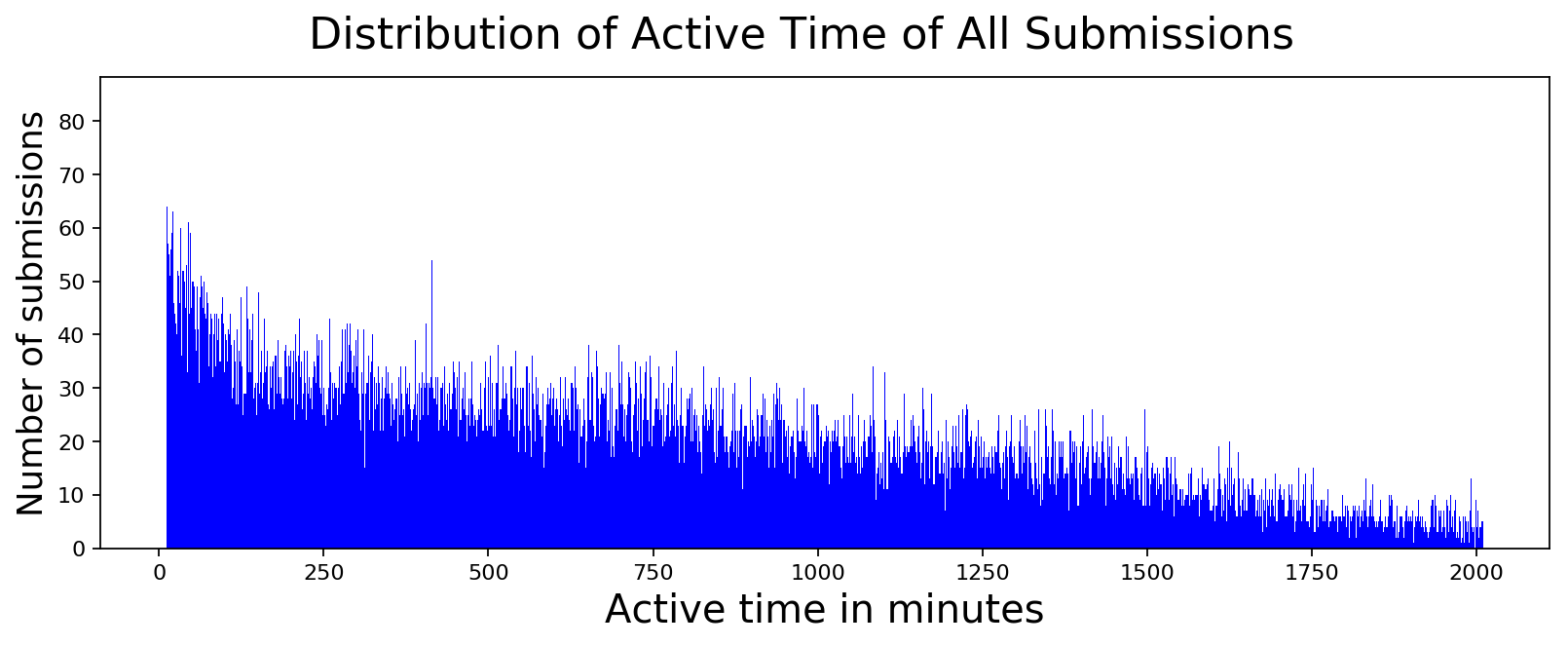
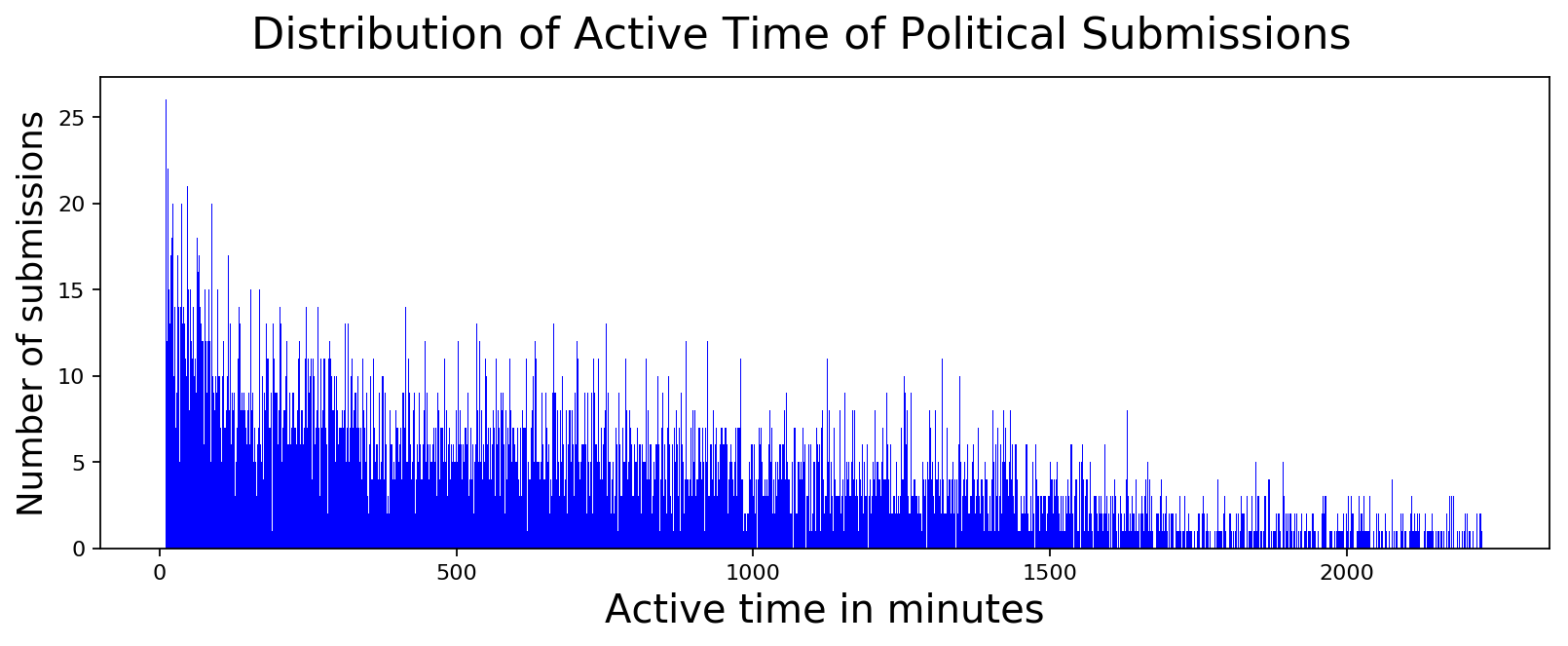
It turns out that non-political posts are similarly active as political posts. Computing median of all posts and political posts shows that political posts actually are slightly less active compared to all posts. I guess political posts are probably occupying a lot more of my visual field whenever I browse r/india and that's probably not true with respect to everybody.
Just for the sake of completeness, we were considering average time to respond as one of the signal but we don't know if paid accounts are following certain simple rules to respond to comments. If so, it should show up as a spike in response time histogram. So let's plot it and see...
comment_diffs = cursor.execute("""
select timediff, count(*)
from
(select
(
cast(strftime('%s', c.posted_at) as integer) -
cast(strftime('%s', d.posted_at) as integer)
)/60 as timediff
from
comments as c
join
submissions as d on c.submission_id==d.submission_id
where
c.posted_by!='AutoModerator'
and c.posted_by NOT LIKE '%bot'
and c.posted_by!='[deleted]'
and timediff>10)
group by
timediff
""").fetchmany(1000)
plot_data([int(x) for x,y in comment_diffs],
[int(y) for x,y in comment_diffs],
'Time diff in minutes', 'Number of comments',
'Number of responses within a specified time',
color='blue', width=0.2)

It looks like there isn't that big a spike if you exclude bots. It slides down naturally as one would expect. Maybe if we look at time to respond for political posts vs non-political posts, we may get some clues...
# Response time to comments for political and all posts
comment_diffs = cursor.execute("""
select timediff, count(*)
from
(select
(
cast(strftime('%s', c.posted_at) as integer) -
cast(strftime('%s', d.posted_at) as integer)
)/60 as timediff
from
comments as c
join
comments as d on SUBSTR(c.parent_comment_id, 4)=d.comment_id
where
c.parent_comment_id!=''
and c.posted_by!='AutoModerator'
and c.posted_by NOT LIKE '%bot'
and c.posted_by!='[deleted]')
group by
timediff
""").fetchmany(1000)
plot_data([int(x) for x,y in comment_diffs],
[int(y) for x,y in comment_diffs],
'Time diff in minutes', 'Number of comments',
'Number of responses within a specified time',
color='blue', width=0.2)
comment_diffs = cursor.execute("""
select timediff, count(*)
from
(select
(cast(strftime('%s',
c.posted_at) as integer)-cast(strftime('%s',
d.posted_at) as integer))/60 as timediff
from
comments as c
join
comments as d
on SUBSTR(c.parent_comment_id,
4)=d.comment_id
where
c.parent_comment_id!=''
and c.posted_by!='AutoModerator'
and c.posted_by NOT LIKE '%bot'
and c.posted_by!='[deleted]'
and c.submission_id in (
select
submission_id
from
submissions
where
link_flair_text='Politics'
)
)
group by
timediff
""").fetchmany(1000)
plot_data([int(x) for x,y in comment_diffs],
[int(y) for x,y in comment_diffs],
'Time diff in minutes', 'Number of comments to political submissions',
'Number of responses to political submissions within a specified time',
color='blue', width=0.2)
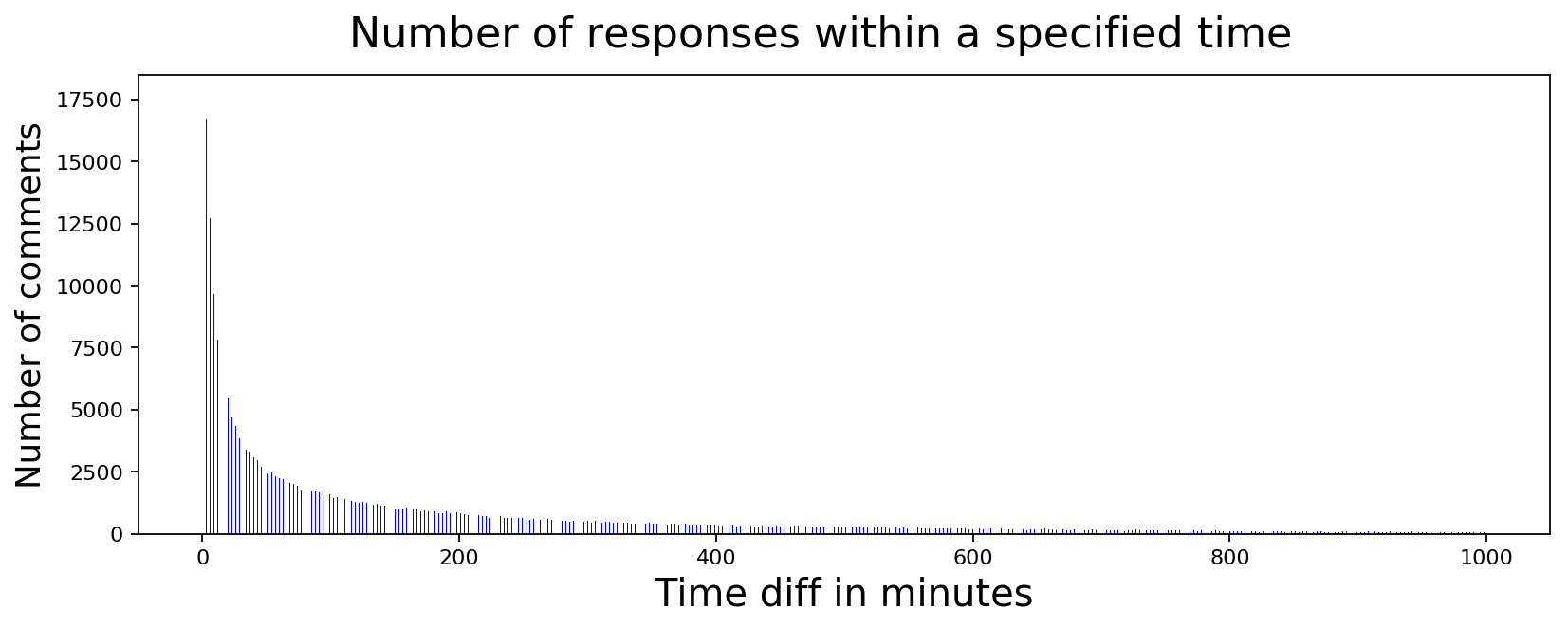
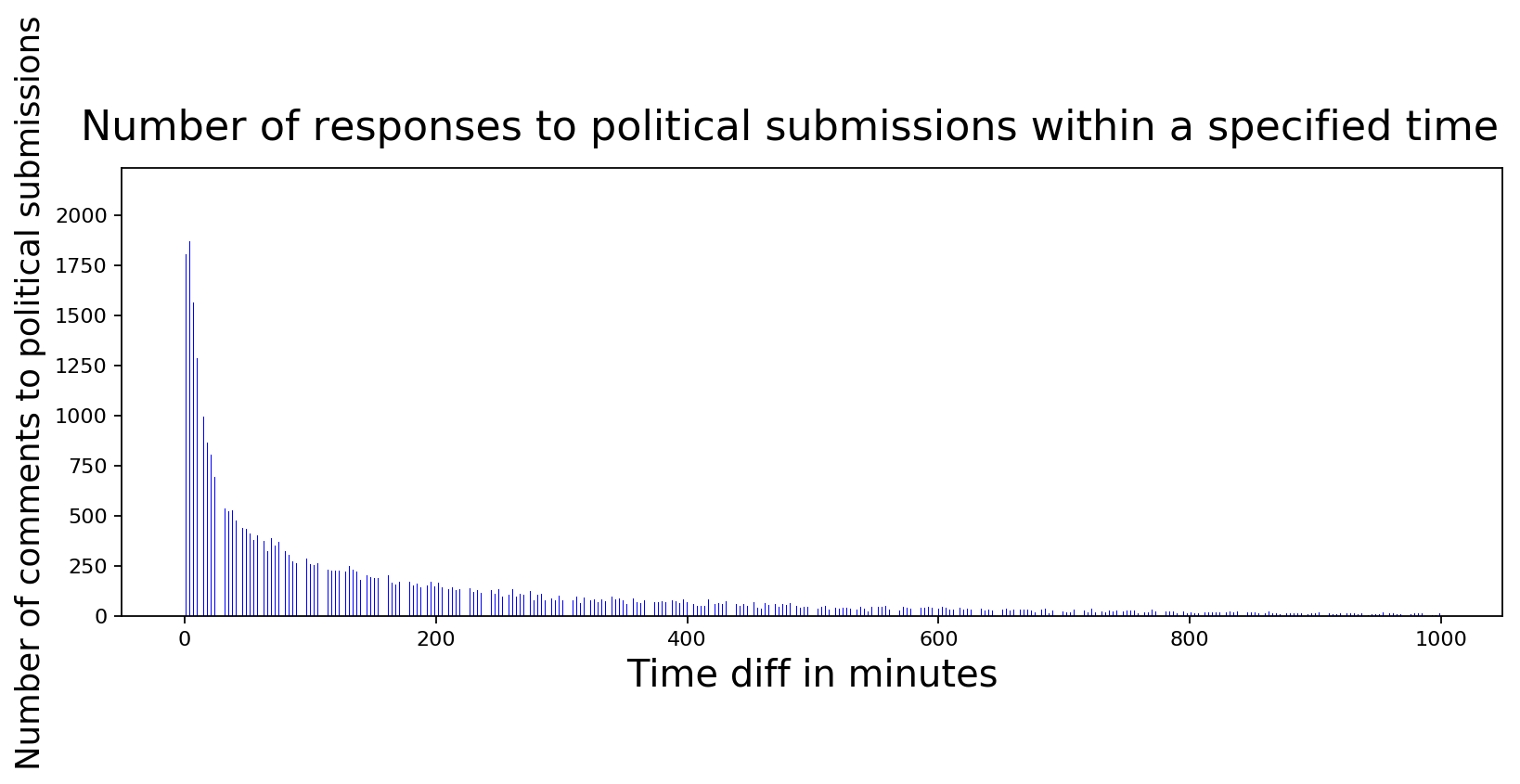
No luck here either. It seems like political posts follow a similar response times as non-political posts. So far I don't have enough information to detect whether there are any paid accounts trying to influence the users to think certain way or not. My gut feeling says that there definitely are people with bad intentions but I haven't found a signal yet to differentiate them. I guess the search continues...
Fancy Wordclouds
If you thought that this analysis will complete without word clouds, you must be dreaming. Let's see what are the most common words in political submission titles and comments...
import base64
import operator
from wordcloud import WordCloud
# Submission title word cloud
submission_title = ''
for b64text in cursor.execute(
"select title from submissions where link_flair_text='Politics'").fetchall():
text = base64.b64decode(b64text[0])
submission_title += text + ' '
title_wordcloud = WordCloud(
width=1200, height=600, background_color='white').generate(submission_title)
fig = plt.figure(figsize=(12,6), dpi=80)
plt.imshow(title_wordcloud, interpolation='bilinear')
plt.title('Wordcloud of Political Submission Titles', fontsize=20)
plt.axis("off")
Output:
(-0.5, 1199.5, 599.5, -0.5)

# Submission text word cloud
submission_text = ''
for b64text in cursor.execute(
"select content from submissions where link_flair_text='Politics'").fetchall():
text = base64.b64decode(b64text[0])
submission_text += text + ' '
text_wordcloud = WordCloud(
width=1200, height=600, background_color='white').generate(submission_text)
fig = plt.figure(figsize=(12,6), dpi=80)
plt.imshow(text_wordcloud, interpolation='bilinear')
plt.title('Wordcloud of Political Submission Content', fontsize=20)
plt.axis("off")
Output:
(-0.5, 1199.5, 599.5, -0.5)
Code and Extras
import avro
import base64
import io
import os
import praw
import sqlite3
import stylometry
import sys
from avro.datafile import DataFileReader
from avro.io import DatumReader
from datetime import datetime
from multiprocessing.dummy import Pool as ThreadPool
from stylometry.cluster import *
from stylometry.extract import *
epoch = datetime(1970,1,1)
def safe_int(val):
if val != None:
return val
else:
return 0
class RedditDataLoader(object):
def __init__(self):
self.conn = sqlite3.connect('reddit.db')
def get_author_info(self, reddit, author_name):
try:
author = reddit.redditor(author_name)
user_since = datetime.utcfromtimestamp(author.created_utc)
return (
author_name,
"'%s', '%s', %f, %f" % (
author_name, user_since, author.link_karma,
author.comment_karma))
except Exception, e:
print 'Failed with exception', e
return author_name, None
def fetch_author_info(self):
reddit = praw.Reddit(client_id='', client_secret='',
username='', password='', user_agent='script')
cursor = self.conn.cursor()
submission_authors = [item[0]
for item in cursor.execute(
'select distinct(posted_by) from submissions').fetchall()]
comment_authors = [item[0]
for item in cursor.execute(
'select distinct(posted_by) from comments').fetchall()]
all_authors = sorted(list(set(submission_authors + comment_authors)))
print 'Found %d authors' % len(all_authors)
pool = ThreadPool(12)
all_authors_data = pool.map(
lambda author: self.get_author_info(reddit, author), all_authors)
pool.close()
pool.join()
print 'Done fetching data'
for author_name, author_details in all_authors_data:
if author_details==None: continue
self._add_author_details(cursor, author_name, author_details)
def identify_submission_comments(self):
cursor = self.conn.cursor()
comment_submissions = {}
comment_parents = {}
comments = cursor.execute(
"""select
comments.comment_id, submissions.submission_id
from submissions
join comments on
submissions.submission_id=SUBSTR(comments.parent_comment_id,4)""").fetchall()
print 'Find submission of comments which have already been tagged that way'
for comment in comments:
comment_submissions[comment[0]] = comment[1]
print 'Found %d comments that are direct replies to a submission' % len(comments)
print 'Finding parents of all comments'
no_sub_comments = cursor.execute("""
select comment_id, SUBSTR(parent_comment_id, 4) as parent_id
from comments""").fetchall()
for comment in no_sub_comments:
comment_parents[comment[0]] = comment[1]
print 'Found %d comments' % len(no_sub_comments)
# Find submission of all the comments
print 'Find submissions that comments belong to'
for comment in comment_parents:
if comment not in comment_submissions:
submission = ''
parent = comment_parents[comment]
while (
parent != None and
parent not in comment_submissions and
parent in comment_parents):
parent = comment_parents[parent]
if parent != None and parent in comment_submissions:
comment_submissions[comment] = comment_submissions[parent]
print 'Updating submission id for %d comments' % len(comment_submissions)
for comment in comment_submissions:
cursor.execute(
"update comments set submission_id='%s' where comment_id='%s'" % (
comment_submissions[comment], comment))
print 'Committing changes'
self.conn.commit()
print 'Done making all the changes'
def read_data(self, submission_file_name, comment_file_name):
cursor = self.conn.cursor()
# read and load submissions
print 'Reading and loading submissions data'
submission_file = DataFileReader(open(submission_file_name, 'rb'), DatumReader())
for submission in submission_file:
self._add_submission_details(cursor, submission)
# read and load submissions
print 'Reading and loading comments data'
comment_file = DataFileReader(open(comment_file_name, 'rb'), DatumReader())
for comment in comment_file:
self._add_comment_details(cursor, comment)
def create_tables(self):
c = self.conn.cursor()
# If some tables exist, we don't need to create new ones
c.execute("SELECT count(*) FROM sqlite_master where type='table'")
if c.fetchone()[0] > 0:
return
c.execute('''CREATE TABLE users
(user_id text PRIMARY KEY, user_since timestamp,
link_karma real, comment_karma real)''')
c.execute('''CREATE TABLE submissions
(submission_id text PRIMARY KEY, title text, content text,
link_flair_text text, posted_at timestamp, posted_by text,
upvotes int, downvotes int, score int, num_comments int)''')
c.execute('''CREATE TABLE comments
(comment_id text PRIMARY KEY, submission_id text, parent_comment_id text,
content text, posted_at timestamp, posted_by text,
upvotes int, downvotes int, score int)''')
self.conn.commit()
def _add_submission_details(self, cursor, submission):
try:
created_at = datetime.utcfromtimestamp(int(submission['created_utc']))
cursor.execute("SELECT * FROM submissions WHERE submission_id='%s'" % submission['id'])
if cursor.fetchone() != None:
return
values = "'%s', '%s', '%s', '%s', '%s', '%s', %d, %d, %d, %d" % (submission['id'],
base64.b64encode(submission['title'].encode('utf-8')),
base64.b64encode(submission['selftext'].encode('utf-8')),
submission['link_flair_text'], created_at, submission['author'],
safe_int(submission['ups']), safe_int(submission['downs']),
safe_int(submission['score']), safe_int(submission['num_comments']))
cursor.execute("INSERT INTO submissions VALUES (%s)" % values)
self.conn.commit()
except ValueError,e:
pass
except Exception, e:
print submission, e
def _add_comment_details(self, cursor, comment):
created_at = datetime.utcfromtimestamp(int(comment['created_utc']))
cursor.execute("SELECT * FROM comments WHERE comment_id='%s'" % comment['id'])
if cursor.fetchone() != None:
return
values = "'%s', '', '%s', '%s', '%s', '%s', %d, %d, %d" % (
comment['id'], comment['parent_id'],
base64.b64encode(comment['body'].encode('utf-8')),
created_at, comment['author'], safe_int(comment['ups']),
safe_int(comment['downs']), safe_int(comment['score']))
cursor.execute("INSERT INTO comments VALUES (%s)" % values)
self.conn.commit()
def _add_author_details(self, cursor, author_name, author_details):
try:
cursor.execute("SELECT * FROM users WHERE user_id='%s'" % author_name)
if cursor.fetchone() != None:
return
cursor.execute('INSERT INTO users VALUES (%s)' % author_details)
self.conn.commit()
except Exception, e:
print e
if __name__=='__main__':
data_loader = RedditDataLoader()
#data_loader.identify_submission_comments()
#data_loader.create_tables()
#data_loader.read_data('data/submissions.avro', 'data/comments.avro')
#data_loader.fetch_author_info()
print 'Done loading'